Mapping a third party billing system database with Python
Summary: By using Python & SQL I was able to recreate a database with FK references, which meant that I could use SchemaSpy, a java based app, to build a data catalogue with drawn maps.
Scenario: Third party billing system database has no PKs, FKs or FK references. Also no documentation was provided detailing joins.
Connecting to SQL Server
I connected to the SQL Server Database which hosted the live billing system using SQL Alchemy and pyodbc. Obviously for this demo, I have manually X'ed out the log in details
from sqlalchemy import create_engine
import pyodbc
import urllib
#Connect to Server and Database
server = 'xxxxxxxxx'
database = 'xxxxxxxxx'
UID = 'xxxxxxxxxx'
PWD = 'xxxxxxxxxx'
params = urllib.parse.quote_plus("".join(['DRIVER={SQL Server Native Client 11.0};SERVER=',
server,';DATABASE=',database,';UID=',UID,';PWD=',PWD,';']))
engine = create_engine("mssql+pyodbc:///?odbc_connect=%s" % params)The following SQL script is saved as "Whole Table Script.sql" in the same folder as my .ipynb file (I am an avid user of Jupyter Notebooks). It will return a view of every column for every table and its data type in the database. In the case of this particular database I already know that 'id' is the PK and that columns with the suffix FK are foreign keys.
SELECT tbl.name as table_name
, c.name as Column_Name
, c.column_id
, iif(right(c.name,2)in('fk','id')
and t.Name = 'int','bigint', t.Name) as Data_type
, convert(varchar,iif((t.Name = 'nvarchar' and c.max_length = -1),'max',
iif(t.Name = 'nvarchar', cast(c.max_length/2 as varchar) ,
iif( t.Name in ('varchar','char'), cast(c.max_length as varchar),
iif( t.Name in ('decimal','numeric'),
cast(c.precision as varchar) + ',' + cast(c.scale as varchar),
iif(t.Name = 'datetime2'
,cast(c.scale as varchar) ,'')))))) as length
, iif(c.name = 'id', 'not null' ,iif(c.is_nullable=1,'null','not null')) as nulls
, iif(c.name = 'id',tbl.name+'fk',null) as pk_converted_to_fk
, iif(c.name like '%fk',c.name,null) as fk
, iif(c.name = 'id','PK',iif(c.name like '%fk','FK',null)) as PK_FK
FROM sys.columns c
inner join sys.types t
ON c.user_type_id = t.user_type_id
left join sys.index_columns ic
ON ic.object_id = c.object_id AND ic.column_id = c.column_id
left join sys.indexes i
ON ic.object_id = i.object_id AND ic.index_id = i.index_id
inner join sys.tables tbl
ON c.object_id = tbl.object_id
order by 1Pandas DataFrames
A combination of SQL alchemy & Pandas is used to read the results of my saved query directly into a Pandas DataFrame. In which I further develop by removing duplicates (this can happen when reading queries directly into a DataFrame, better practice would be to run the query on the server in a scheduled task beforehand and read the results directly from a table). I also create a DataFrame of unique table names and remove any tables prefixed with tmp.
import pandas as pd
query = open(r"Whole Table script.sql","r")
sql_q = pd.read_sql_query(query.read(),engine)
df = pd.DataFrame(sql_q)
engine.dispose()
query.close()
df = df.drop_duplicates()
df_uniq = df.table_name.unique()
#Remove all TMP tables that should not be in the live database!
df_uniq_2 = [i for i in df_uniq if i[:3].lower() != "tmp"]Building an SQL script to create a Database
The following ‘for each’ method builds an SQL create table script for each unique table, ensuring that PKs are addressed. The query is later run against the destination database. The destination DB in this case is a mySQL DB therefore I have converted Nvarchar(max) to just nvarchar(255) and Datetime2 into datetime.
texta = "use jpg_energy \n;\n"
for i in df_uniq_2:
df_tmp = df[df.table_name == i ]
texta += "".join(["create table ", i, " (",'\n'])
for x in df_tmp.index:
y = df_tmp.Data_type[x] +"("+ df_tmp.length[x]+ ")"
if df_tmp.Data_type[x] == 'datetime2':
y = 'datetime'
if df_tmp.Data_type[x] +"("+ df_tmp.length[x]+ ")" == 'nvarchar(max)':
y = 'nvarchar(255)'
texta += "".join([',' if df_tmp.column_id[x] > 1 else ''])
texta += "".join(['\t','`',df_tmp.Column_Name[x],'`',' '])
texta += "".join(y if len(df_tmp.length[x]) > 0 else df_tmp.Data_type[x])
texta += "".join([' ',df_tmp.nulls[x].upper()])
texta += "".join([' PRIMARY KEY' if df_tmp.column_id[x] == 1 else ''])
texta += "\n"
texta += ");\n\n"
import os
text_file = open("Create Database.sql", "w")
n = text_file.write(texta)
text_file.close()Matching Process
The process now is to create a list of every potential foreign keys and remove the suffix ‘fk’, this would potentially match back to a table name. However, in this particular database compound names are used for some foreign keys such as parentAccountfk which would join onto the Account table ID column.
#we have a list of every table in df_uniq_2
#we need a list of every fk sans "fk", broken down into potential fks
df_fk = df[df.fk.notnull()]
#Drop any table that contains tmp
#assign/lambda way will avoid the SettingwithCopyWarning
df_fk = df_fk.assign(table_name_3=lambda x: x['table_name'].str[:3].str.lower())
df_fk = df_fk[df_fk.table_name_3.str.lower() != 'tmp']
df_fk = df_fk.drop(['table_name_3'], axis=1)
#Drop uneeded columns
df_fk = df_fk.drop(['column_id', 'Data_type','length','nulls',
'pk_converted_to_fk','Column_Name','PK_FK'], axis=1)
#add column of first potential match - if there is a full match then no need to proceed etc.
df_fk["table_match_1"] = df_fk["fk"].str[:-2]
This function breaks the fk name down into parts based on the capitalisation of letters. The most words in an FK is six, for example. parentUkCommSiteBillEntry UkCommSiteBillEntry CommSiteBillEntry SiteBillEntry BillEntry Entry Each one of these could be a table in the database and be the intended match.
def splitWord(word):
return [char for char in word]
def countCaps(word):
counta = []
x = -1
word = splitWord(word)
for i in word:
x += 1
if i.isupper():
counta.append(x)
counta.reverse()
return counta
def returnWord(word,val):
x = countCaps(word)
try:
word = word[x[val]:]
except:
word = ''
return word
df_fk["table_match_2"] = df_fk.apply(lambda x: returnWord(x['table_match_1'], 0), axis=1)
df_fk["table_match_3"] = df_fk.apply(lambda x: returnWord(x['table_match_1'], 1), axis=1)
df_fk["table_match_4"] = df_fk.apply(lambda x: returnWord(x['table_match_1'], 2), axis=1)
df_fk["table_match_5"] = df_fk.apply(lambda x: returnWord(x['table_match_1'], 3), axis=1)
df_fk["table_match_6"] = df_fk.apply(lambda x: returnWord(x['table_match_1'], 4), axis=1) The next step is to create left joins using the ‘merge’ process of a Pandas Dataframe. I decided to do this individually rather than roll into a function so that I could check as I matched.
df_table_list = pd.DataFrame(df_uniq_2) #create dataframe of unique table names
df_table_list.columns= ['table_name_join'] #rename column as table_name
#create lower case joins
df_fk['table_match_1'] = df_fk['table_match_1'].apply(lambda x: x.lower())
df_fk['table_match_2'] = df_fk['table_match_2'].apply(lambda x: x.lower())
df_fk['table_match_3'] = df_fk['table_match_3'].apply(lambda x: x.lower())
df_fk['table_match_4'] = df_fk['table_match_4'].apply(lambda x: x.lower())
df_fk['table_match_5'] = df_fk['table_match_5'].apply(lambda x: x.lower())
df_fk['table_match_6'] = df_fk['table_match_6'].apply(lambda x: x.lower())
df_table_list['table_name_lower'] = df_table_list['table_name_join'].apply(lambda x: x.lower())
#Match process 1
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_1', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_1'}) #rename first column
#Match process 2
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_2', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_2'}) #rename first column
#Match process 3
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_3', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_3'}) #rename first column
#Match process 4
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_4', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_4'}) #rename first column
#Match process 5
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_5', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_5'}) #rename first column
#Match process 6
df_fk = df_fk.merge(df_table_list, how='left', left_on='table_match_6', right_on='table_name_lower')
df_fk = df_fk.drop(['table_name_lower'], axis=1) # remove match key
df_fk =df_fk.rename(columns={'table_name_join': 'table_6'}) #rename first columnI used Numpy to remove NAN, which essentially is a null where no match was found via a join. This was then rolled up into a single column whether a table was matched to a foreign key. This is in preparation for building the Alter table FK reference script.
import numpy as np
df_fk = df_fk.replace(np.nan, '', regex=True)
def table_join(table1,table2,table3,table4,table5,table6):
if table1 != '':
x = table1
elif table2 != '':
x = table2
elif table3 != '':
x = table3
elif table4 != '':
x = table4
elif table5 != '':
x = table5
elif table6 != '':
x = table6
else:
x = ''
return x
df_fk["fk_Parent"] = df_fk.apply(lambda x: table_join(x['table_1']
,x['table_2'],x['table_3']
,x['table_4'],x['table_5']
,x['table_6'] ), axis=1)
df_fk = df_fk.drop(['table_match_1','table_match_2','table_match_3'
,'table_match_4','table_match_5','table_match_5','table_match_6'], axis=1)
df_fk = df_fk.drop(['table_1','table_2','table_3','table_4','table_5','table_5','table_6'], axis=1)
#removes unmatched, there are instances of FKs where a table does not exist yet (in development)
df_fk = df_fk[df_fk['fk_Parent'] != ""]
Creating the Alter Table script
Now, I am left with a DataFrame that consists of FKs and the tables that they join onto, I already know that the ID column of a table is the attended match therefore I can create a script dynamically, which will produce all of the FK reference metadata that SchemaSpy requires.
#this is for references then run both scripts then run SchemaSpy
texta = "use jpg_energy \n;\n"
for i in df_fk.index:
#ALTER TABLE Orders
#ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);
texta += "".join(["ALTER TABLE ", df_fk.table_name[i],
" ADD FOREIGN KEY (",df_fk.fk[i],") REFERENCES ",
df_fk.fk_Parent[i], "(ID) \n;\n"
])
text_file = open("Create Database FK References.sql", "w")
n = text_file.write(texta)
text_file.close()
Connecting to the Destination DB and running the Scripts
A simple connection to the mysql DB I created locally and a function which runs each part of the script individually, the end of each part is signified by a semicolon. Unlike when I ran the first script, the dynamically created scripts are made up of short lines of code, SQLAlchemy needs these blocks individually fed into it.
#Connect to Server and Database
from sqlalchemy import create_engine
import pymysql
# Connecting to MySQL server at localhost using PyMySQL DBAPI
engine = create_engine("mysql+pymysql://root:XXXXXXX@localhost/jpg_energy")
from sqlalchemy import text
def run_script_line_by_line(sql_file):
# Iterate over all lines in the sql file
sql_command = ''
for line in sql_file:
sql_command += line.strip('\n')
# If the command string ends with ';', full statement complete execute it
if sql_command.endswith(';'):
# Try to execute statement
try:
engine.execute(text(sql_command))
except Exception as e: print(e)
#'Engine' object has no attribute 'commit'
# this happened when i used engine.commit
# Clear command string for next iteration
finally:
sql_command = ''
#Create the database
sql_file = open("Create Database.sql","r")
run_script_line_by_line(sql_file)
#Create the fk references
sql_file = open("Create Database FK References.sql","r")
run_script_line_by_line(sql_file)
Running SchemaSpy
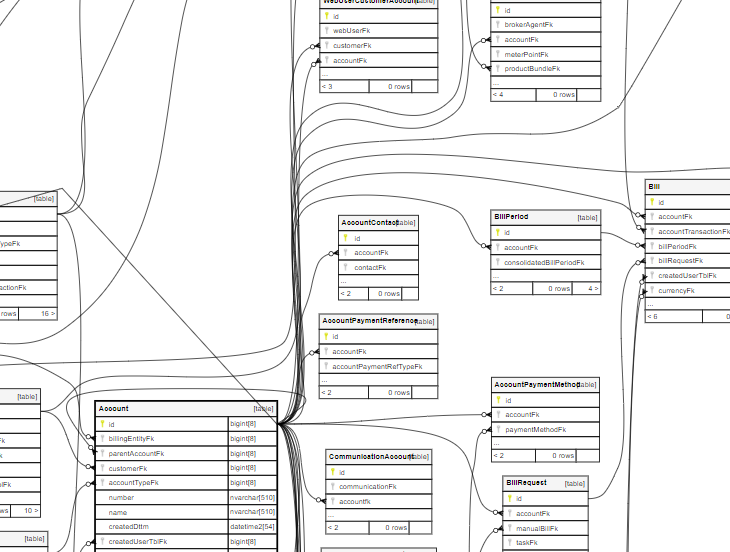
At this point I have cloned the third party database but amended it to have FK references and be able to reside in a mySQL database. All I needed to do was install Java 8 and SchemaSpy and run a Java command to create the database catalogue and maps.
Java -jar schemaspy-6.1.0.jar -t mysql
-host localhost -db jpg_energy -s jpg_energy -u root -p PWORD
-dp "C:\Program Files (x86)\MySQL\Connector J 8.0\mysql-connector-java-8.0.21.jar"
-o jpg_energy -cat catalog -vizjs -renderer :cairo